
The system as a whole is called ARGON; but given all the other modules that comprise an ARGON node's kernel, all that's left to be "ARGON" itself is the code shared by components that doesn't fit into any one component, yet doesn't deserve a component in its own right.
The ARGON module comprises:
* HYDROGEN code for the first stage of the kernel startup sequence. This initialises IRON, and CHROME, then compiles and runs HELIUM, LITHIUM, NITROGEN, WOLFRAM, and all the other kernel components.
- The CHROME (with embedded HYDROGEN where necessary to use hardware crypto accelerators or for hand-coded inner loops) library of cryptographic primitives and classification / clearance operations referred to in the security model.
- Infrastructure for managing debugging mode in entities. CHROME needs to know if the entity is in debug mode so it can provide single-stepping, breakpoints, and so on for CHROME code. WOLFRAM and MERCURY need to know if tracing of uses of their services is requested, and if so, to be able to easily submit log messages down the debugging channel. Ok, this one's big enough that I should probably come up with an element name for it and make it a thing of its own...
...and doubtless many other little utilities that are needed in time will accumulate.
Here's a diagram showing roughly how the components fit together on a running node.
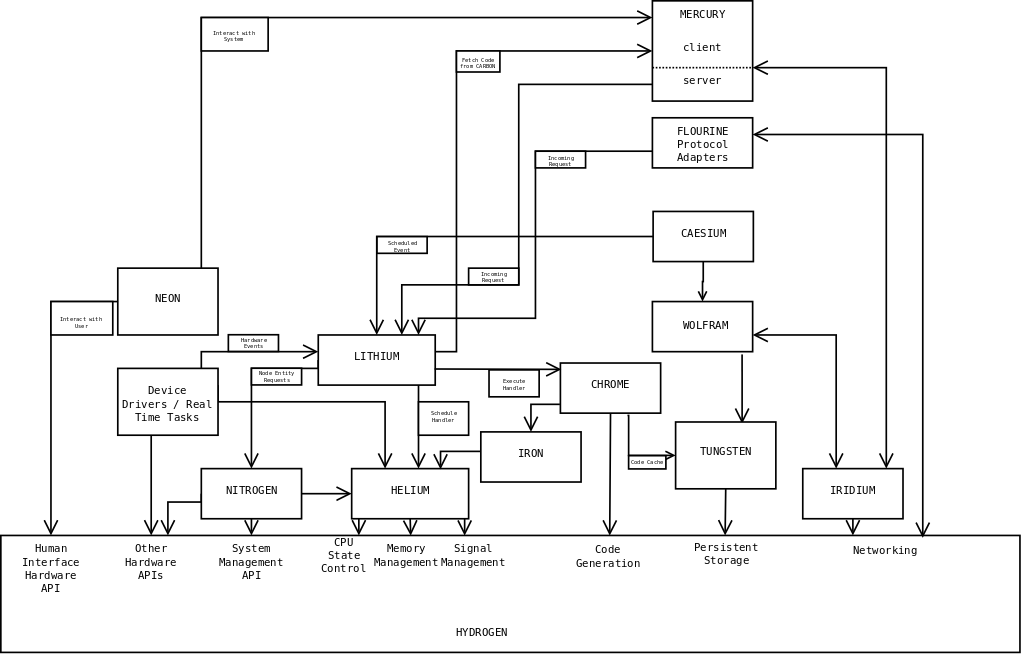{kind=link}
Variations in Node Configuration
I've written the above boot process for running a "full" ARGON node that handles both TUNGSTEN storage and runs LITHIUM handlers.
However, a node might be configured without any TUNGSTEN mass storage devices, and have to access everything remotely via WOLFRAM.
Likewise, the three main sources of LITHIUM handler requests - MERCURY/CARBON networking and CAESIUM scheduled events - should be individually configurable on a node. Whether a node is published in the volume ID for external requests or not is configurable, and allows nodes to be set up that only handle intra-cluster requests. Turning all of these off would make a node that exists purely for TUNGSTEN storage.
Embedded Systems
ARGON can also drive embedded systems, too.
At the most basic level, HYDROGEN, optionally with HELIUM and/or IRON and CHROME as well, is a fine low-level platform for embedded development. Such systems aren't full ARGON nodes as they don't run WOLFRAM.
But it should also be possible to build an ARGON node without TUNGSTEN, without WOLFRAM distributed processing or CAESIUM, and only accepting MERCURY requests to its NITROGEN node entity - which then provides functionality to access the embedded system's custom software. Such a node could join a cluster, purely to provide a single volume/node entity representing itself.
Also, not all nodes need to be part of a cluster. WOLFRAM will happily support a cluster with only one node in it, which can be grown later, but it is possible to set up a node with local TUNGSTEN storage and entities and everything, but without WOLFRAM. It would have a node entity which is also a volume entity, but no need for cluster entities.
Thin Clients, Fat Clients and Mobile Devices
A thin client in the ARGON world is a node that just provides a NEON interface, letting a user log into a user agent by downloading a user interface to run locally. It might be part of a cluster for ease of administration as a whole, and it might have TUNGSTEN storage for local caching, but it wouldn't mirror any volumes.
A public thin client might provide its own user interface without a user agent; its CARBON browsing and NEON user-interfacing would just be anonymous, or identified as from the actual node entity of the thin client device itself.
However, a more powerful device could join a cluster as a roving node and mirror the user agent entity itself. Public access to the user agent would be through the mirrors of it on non-roving nodes in the cluster, but the local copy allows for operation when the node is isolated from the cluster, and resynchronisation upon reconnection. That could earn the term "fat client".
Mobile devices such as tablet computers and smartphones can provide full general NEON user interface capabilities like either of the above, or go for a more specialist interface, optionally connecting to a user agent entity through a MERCURY endpoint that lets them access private state such as address books and messages, much like modern smartphones connect to sync and messaging services.